



1. 引言
Ollama 支持在多个平台上安装和运行(LLM)大型语言模型,包括 macOS、Linux 以及 Windows 预览版。安装过程简单便捷,只需访问 Ollama 的官方网站下载相应平台的安装包即可完成安装。
1. 环境准备
在开始之前,确保你已经安装了以下工具:
一台Liunx/windows电脑
已安装docker
建议使用至少 4 核的任何现代 CPU,对于运行 13B 模型,建议使用至少 8 核的 CPU。
运行7B模型至少需要8GB的可用内存,13B模型需要16GB,而33B模型则需要32GB的内存。
GPU(可选) 运行 Ollama 不需要 GPU,但它可以提高性能,尤其是运行较大的模型。如果您有 GPU,可以使用它来加速 定制模型的训练。
3.安装Ollama
执行docker安装Ollama命令
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
进入Ollama容器
docker exec -it ollama bashOllama运行llama3大语言模型
ollama run llama3
可能会因为网络原因下载失败,再次执行ollama run llama3命令即可
看到success字样就llama3模型就运行成功了
 测试大模型
测试大模型
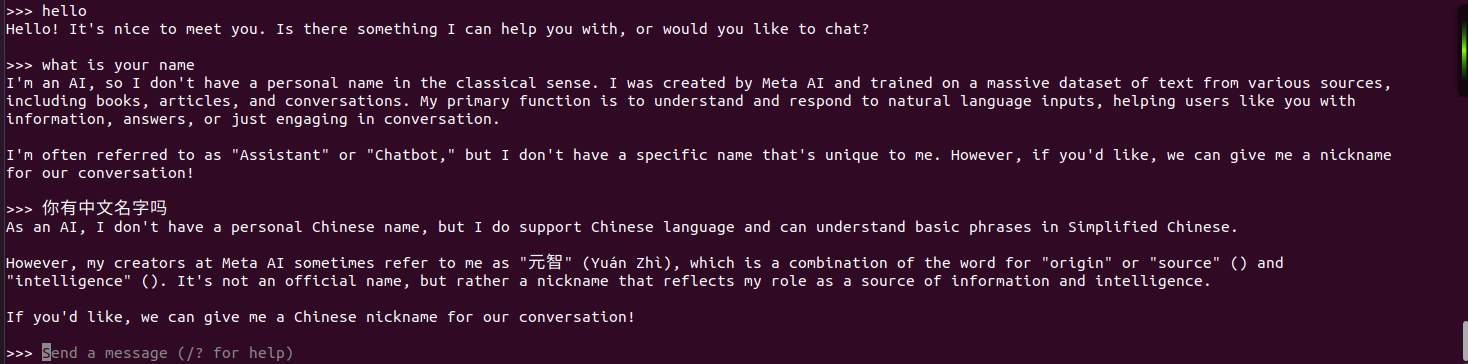
其他模型运行命令
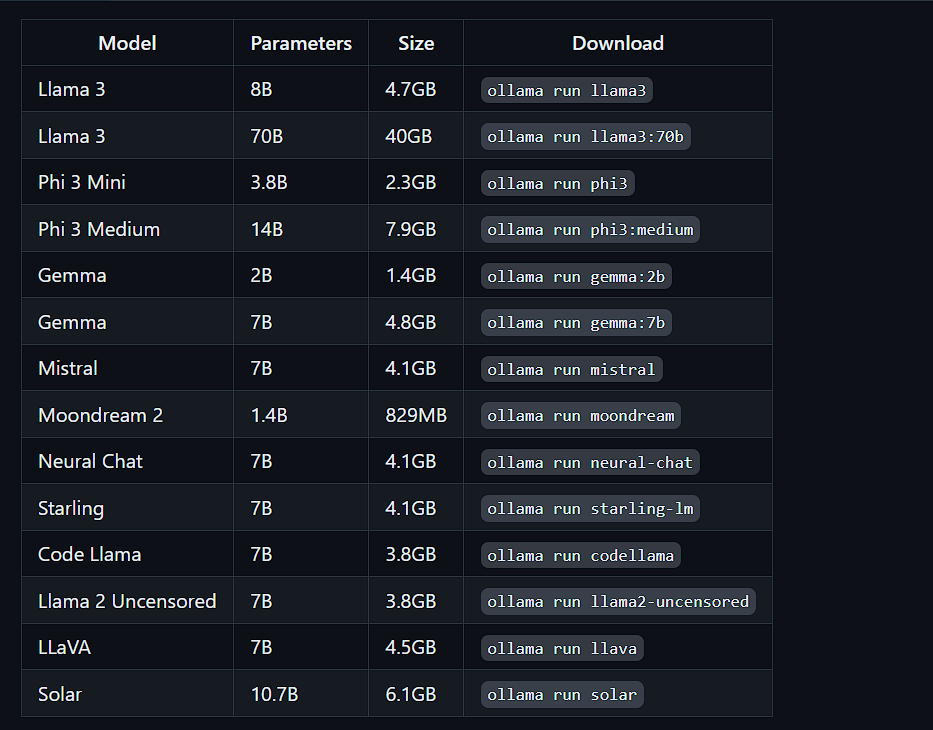
4.安装Open WebUI
执行docker安装Open WebUI命令
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main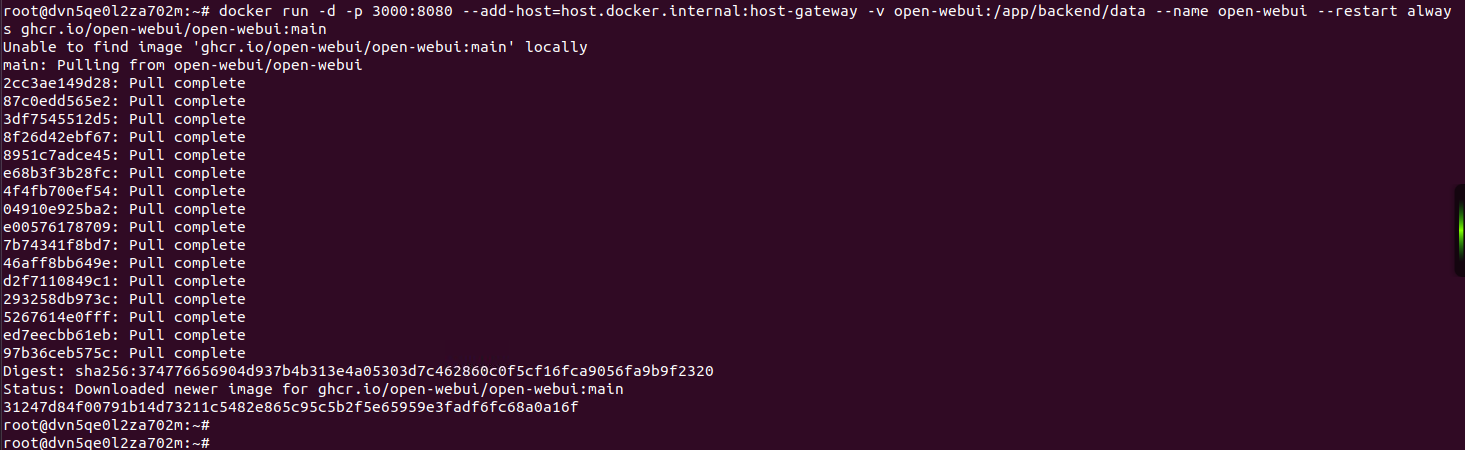
访问Open WebUI
地址:http://127.0.0.1:3000/
第一次访问注册的账号默认就是系统管理员
选择左上角模型
使用效果
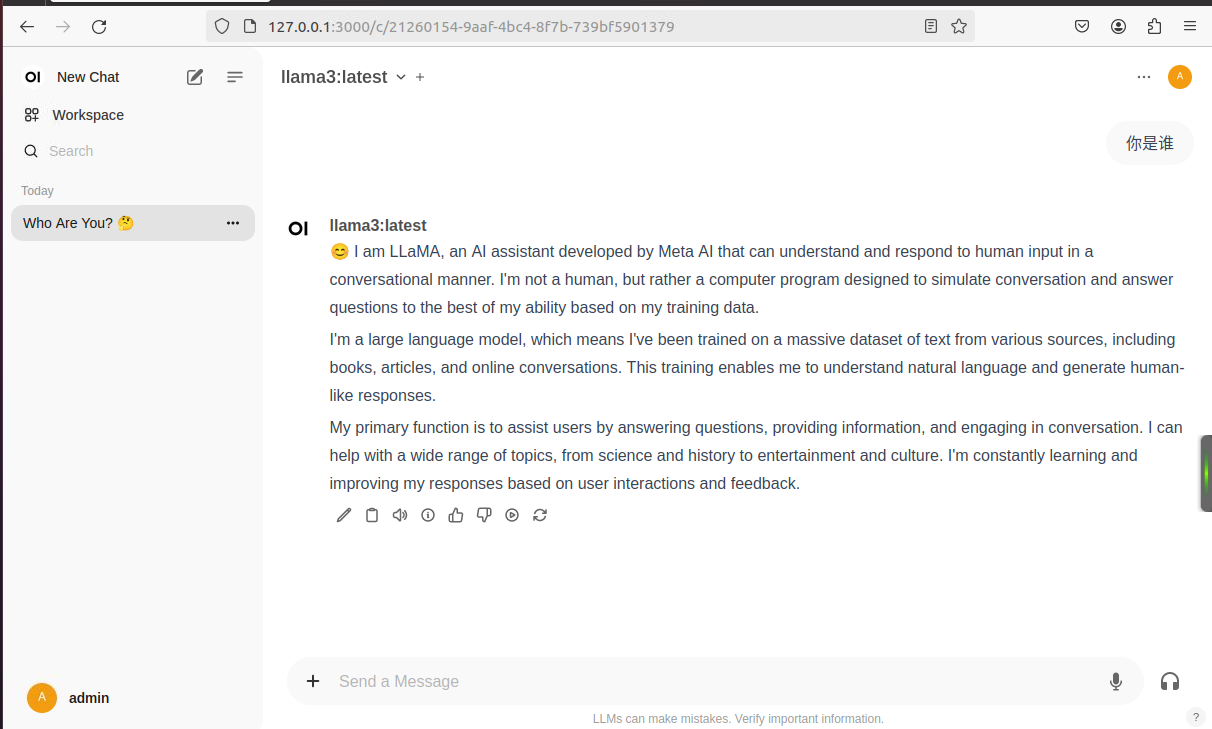
你可以根据需要进一步选择合适的模型,为你的实际应用场景提供支持。
评论区